Python | 騒音計のデータを時系列データベースに保存する(IoT x Database , TimescaleDB)
- 2023.09.12
- データベース

みなさん、こんにちは!
今回は前回の続きとして、騒音計の時系列データをデータベースに保存してみようと思います。
前回の記事↓↓

データを保存する
時間とその時のHzをデータベースに記録していきます。
データ数
時間間隔として1sec毎に書き込みを行うとします。
レコード数は 60sec * 60min * 24 = 86400 となります。
記録先
今回はDB(TimescaleDB)とAPを同一の筐体に設置し、逐一DBに書き込んでいきます。

DB側の設定
TimescaleDBに以下のようなDB、テーブルを作成します。
DB:noiseDB
Table:noise
テーブル作成
テーブルは以下のように作ります。
Create table noise( time timestamp, noise float, sensor varchar(10))ハイパーテーブル作成
TimescaleDBは「ハイパーテーブル」と「チャンク」で構成されます。
データが増えた場合は、チャンク単位でデータを削除することが出来ます。
ハイパーテーブル
├─ チャンク1
├─ チャンク2
…
├─ チャンクX
ハイパーテーブルは「create_hypertable関数」を用いて作成します。
※ 基本的にはデータが入っていない状態で実施します。↓以下のようなエラーが出ます。

-- 書き方:Select create_hypertable('テーブル名', '時間列', チャンクサイズ)
Select create_hypertable('noise', 'time', chunk_time_interval => INTERVAL '1 day');chunk_time_intervalでチャンクに入るデータサイズを決めることが出来ます。
デフォルトは7日で、今回は24時間にします。

既にデータが入っているテーブルに対してだと、「migrate_data => ture」とすれば処理できます。
SELECT create_hypertable('noise', 'time',chunk_time_interval => INTERVAL '1 day',migrate_data => true);このnoiseテーブルに対して、データを書き込んでいきます。
以下のクエリを実行することで、チャンクの設定情報が確認できます。
SELECT h.table_name, c.interval_length
FROM _timescaledb_catalog.dimension c
JOIN _timescaledb_catalog.hypertable h
ON h.id = c.hypertable_id;プログラム
前回のプログラムを改良します。
import pyaudio
import numpy
import librosa.display
import datetime
import time
import psycopg2
#------------------------------------------------------------
#センサーID
#------------------------------------------------------------
SENSOR_ID = "S00001"
#------------------------------------------------------------
#定数
#------------------------------------------------------------
CHUNK = 44100
RATE = 44100
FORMAT = pyaudio.paInt16
CHANNELS = 1
SLEEPTIME = 1.0 #sec
#------------------------------------------------------------
#グローバル変数化
#------------------------------------------------------------
dB_list = numpy.empty(0)
connector = psycopg2.connect('postgresql://{user}:{password}@{host}:{port}/{dbname}'.format(
user="postgres", #ユーザ
password="passw0rd", #パスワード
host="localhost", #ホスト名
port="5432", #ポート
dbname="example")) #データベース名
#------------------------------------------------------------
#postgreコネクション
#------------------------------------------------------------
def pg_insert(t,noise):
with connector:
with connector.cursor() as cursor:
# レコードを挿入
sql = "INSERT INTO noise (time, noise, sensor) VALUES (%s, %s, %s)"
cursor.execute(sql, (t, float(noise),SENSOR_ID))
# コミットしてトランザクション実行
connector.commit()
#------------------------------------------------------------
#ストリーミングで音を取得
#------------------------------------------------------------
def audiostart():
audio = pyaudio.PyAudio()
stream = audio.open( format = FORMAT,
rate = RATE,
channels = CHANNELS,
input = True,
frames_per_buffer = CHUNK)
return audio, stream
#------------------------------------------------------------
#終了処理
#------------------------------------------------------------
def audiostop(audio, stream):
stream.stop_stream()
stream.close()
audio.terminate()
#------------------------------------------------------------
#dB計算
#------------------------------------------------------------
def average_dB(buf):
rms=librosa.feature.rms(y=buf) #RMSを計算
dB=librosa.amplitude_to_db(rms,ref=2*1e-5) #dBを計算
dt = datetime.datetime.today()
avg_dB = numpy.array([dt.strftime('%Y-%m-%d %H:%M:%S.%f'),numpy.mean(dB)])
pg_insert(dt.strftime('%Y-%m-%d %H:%M:%S.%f'),numpy.mean(dB))
print(avg_dB)
return avg_dB
#------------------------------------------------------------
#デシベル計算
#------------------------------------------------------------
def read_plot_data(stream):
global dB_list
data = stream.read(CHUNK)
audiodata = numpy.frombuffer(data, dtype='int16') / float((numpy.power(2, 16) / 2) - 1)
average_dB(audiodata)[1]
time.sleep(SLEEPTIME)
#------------------------------------------------------------
#Main
#------------------------------------------------------------
if __name__ == '__main__':
#録音開始
(audio,stream) = audiostart()
#ノンブロッキング処理
while True:
try:
read_plot_data(stream)
except KeyboardInterrupt:
break
#録音終了
audiostop(audio,stream)データを確認する
約7時間ほどプログラムを実行してみました。データを確認してみます。
1)データ数
24950[sec]/3600 = 6.930555555555556 [hours]
select count(*) from noise
>> 249502)ハイパーテーブルに紐づくチャンクの確認
ハイパーテーブルに紐づくチャンクを確認します。
SELECT show_chunks('noise');
>> _timescaledb_internal._hyper_1_1_chunkハイパーテーブルのサイズは以下のように調べます。単位は「バイト」です。
7時間で約1MBほどなので、1日約3.5MBほどのデータが発生することになります。
SELECT hypertable_size ( 'noise' ) ;
>> 11468803)データを見てみる
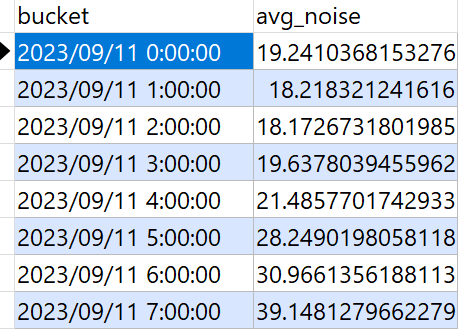
例えば、1時間毎の平均騒音度を見たい場合は以下のように書きます。
SELECT
time_bucket ('1 hour', time) AS bucket,
avg(noise) as avg_noise
FROM noise
Group by bucket
order by bucket asc;夜中から朝方にかけて、徐々に騒音度が増していることが分かります。
データを削除する
データを削除するには 「Delete」もしくは「Drop chunk」を用いることになります。
Deleteで削除した場合は、別途Vacuumを行う必要がありますが、Drop chunkの場合はVaccuumが不要とのことです。
※ ちなみに、現時点でVacuumが必要か否かは、こちらのサイトのクエリを実行すればわかるとのこと。
SELECT
relname,
n_live_tup,
n_dead_tup,
CASE n_dead_tup WHEN 0 THEN 0 ELSE round(n_dead_tup*100/(n_live_tup+n_dead_tup) ,2) END AS ratio
FROM
pg_stat_user_tables ;-
前の記事

データベース | テーブル&データ複製する(テーブルのバックアップを取る) 2023.09.09
-
次の記事
SQL Server | “sqlcmd”をインストールして使ってみる 2023.09.30

